
Importar tabela de dentro um arquivo PDF para o R
É muito comum a necessidade de extrairmos algum dado de um PDF, sejam dados brutos ou presentes em tabelas. Não raras vezes, dá errado. O pacote tabulizer é um pacote da linguagem R, disponível no CRAN desde 2018. O pessoal da Curso-R fez um post sobre este pacote também. Sugiro conferirem, até para entenderem a instalação. O pacote utiliza a biblioteca `Tabula` para extrair tabelas de PDF e depende do `rJava` e, por isso, podem ocorrer alguns errinhos marotos.
Bom, meu intuito aqui é apenas brincar com o pacote e ter uma lista de ferramentas úteis no dia-a-dia do epidemiologista, embora nosso exemplo seja para área ambiental. Prometo atualizar este post e corrigir este detalhe ou gerar mais um post utilizando algum arquivo de boletim do Ministério da Saúde ou Secretaria Estadual. Juro!
Meu primeiro passo é carregar algumas bibliotecas úteis.
library(dplyr)
library(magrittr)
library(ggplot2)
library(patchwork)
library(tabulizer)Vou utilizar para o exercício, este pdf disponível anualmente no site descrito abaixo. Não abordarei a origem do site e nem o propósito da empresa. Apenas usarei como exemplo.
url <- 'https://www.bp.com/content/dam/bp/business-sites/en/global/corporate/pdfs/energy-economics/statistical-review/bp-stats-review-2021-co2-emissions.pdf'Função do Tabulizer: a extract_tables. É aqui que a mágica acontece. Note que alguns warnings ocorrem. Talvez, se eu realizasse o download do arquivo antes e depois a importação com o Tabulizer, isso não aconteceria.
crude_out <- tabulizer::extract_tables(url, pages = 2, output = "data.frame")O objeto crude_out é uma lista contendo a estrutura da tabela extraída do PDF. Vou transformar este objeto em um dataframe e analisá-la melhor. O primeiro item da lista já é nossa tabela. Logo, posso simplesmente ‘jogá-la’ em um outro objeto.
df_out <- as.data.frame(crude_out[[1]])E aqui encontro um ponto interessante. Ao extrair a tabela, é possível perceber algumas configurações estranhas. Mas é normal, pois a formatação das tabelas, geralmente, incluem células mescladas, por exemplo. Ao tentar encaixá-la em uma estrutura de linhas e colunas, digamos, normal, estas dificuldades aparecem.
Vamos analisar a tabela. Percebemos que o cabeçalho está estranho (em amarelo). Vamos nos concentrar na segunda linha, pois faremos dela, o cabeçalho da nossa tabela. A primeira linha vamos excluí-la.
kableExtra::kbl(head(df_out[1:5]))|>
kableExtra::kable_paper(
bootstrap_options = c("striped",
"hover",
"condensed"),
full_width = F,
position = "center"
)|>
kableExtra::row_spec(c(1:2),
background = "yellow"
)| X | X.1 | X.2 | X.3 | X.4 |
|---|---|---|---|---|
| NA | NA | NA | NA | |
| Million tonnes of carbon dioxide | 2010.0 | 2011.0 | 2012.0 | 2013.0 |
| Canada | 550.1 | 554.7 | 551.1 | 564.6 |
| Mexico | 454.8 | 473.0 | 476.7 | 483.2 |
| US | 5495.0 | 5348.4 | 5101.5 | 5268.3 |
| Total North America | 6499.9 | 6376.1 | 6129.4 | 6316.1 |
Para isso, vamos utilizar a função colnames.
colnames(df_out) <- df_out[2,]
kableExtra::kbl(head(df_out[1:5])) |>
kableExtra::kable_paper(
bootstrap_options = c("striped",
"hover",
"condensed"),
full_width = F,
position = "center"
)| Million tonnes of carbon dioxide | 2010 | 2011 | 2012 | 2013 |
|---|---|---|---|---|
| NA | NA | NA | NA | |
| Million tonnes of carbon dioxide | 2010.0 | 2011.0 | 2012.0 | 2013.0 |
| Canada | 550.1 | 554.7 | 551.1 | 564.6 |
| Mexico | 454.8 | 473.0 | 476.7 | 483.2 |
| US | 5495.0 | 5348.4 | 5101.5 | 5268.3 |
| Total North America | 6499.9 | 6376.1 | 6129.4 | 6316.1 |
Depois, deletamos as linhas e colunas indesejadas e arrumamos as colunas e formato.
df_co2_w <- df_out[3:85, 1:12]
df_var_co2 <- df_out[3:85, 13:14]
df_var_co2 <- tidyr::separate(
df_var_co2,
col = c(`2020 2009-19`),
into = c("2020", "2009-19"),
sep = " "
) |>
tibble::add_column(var_2020 = df_var_co2$`2020`)A partir daqui, vamos focar em alguns países. De forma arbitrária.
grupo_pais <- c("Brazil","US","Canada","Sweden",
"Russian Federation",
"China","Japan","South Africa")df_co2_l <- df_co2_w |>
tidyr::pivot_longer(cols = "2010":"2020",
names_to = "Ano",
values_to = "CO2_MT") |>
dplyr::rename(Pais = `Million tonnes of carbon dioxide`) |>
dplyr::filter(!stringr::str_detect(Pais, "Total|Non|which|Other|European Union")) |>
dplyr::mutate(Ano = as.integer(Ano)) |>
dplyr::arrange(desc(CO2_MT))Vamos visualizar em um gráfico, o que conseguimos extrair da tabela.
df_co2_l |>
ggplot2::ggplot(ggplot2::aes(
Ano,
CO2_MT,
group = Pais,
color = Pais)) +
ggplot2::geom_line(show.legend = F) +
ggplot2::geom_point(size = 2, show.legend = F) +
ggplot2::geom_text(
data = dplyr::filter(df_co2_l, Ano == 2020),
ggplot2::aes(label = Pais, color = Pais),
hjust = 0,
nudge_x = 0.1,
fontface = "bold",
size = 3,
show.legend = F
) +
ggplot2::scale_y_log10() +
ggplot2::scale_x_continuous(breaks = seq(2010, 2020, 1),
expand = c(0.01, 0)) +
ggplot2::expand_limits(x = 2022) +
ggplot2::theme_minimal() +
ggplot2::theme(plot.margin = ggplot2::unit(c(0.35, 2, 0.3, 0.35), "cm"))
Não ficou muito bom. Vamos separar os cinco primeiros dos cinco últimos.
top_five <- df_co2_l |>
dplyr::filter(Ano == 2020) |>
head(5) |>
dplyr::pull(Pais)
top_bottom <- df_co2_l |>
dplyr::filter(Ano == 2020) |>
tail(5) |>
dplyr::pull(Pais)
gg1 <- ggplot2::ggplot(data = dplyr::filter(df_co2_l, Pais %in% top_five),
ggplot2::aes(Ano, CO2_MT, group = Pais, color = Pais)) +
ggplot2::geom_line() +
ggplot2::geom_point(size = 2) +
ggplot2::labs(color = "Top five") +
ggplot2::theme_minimal()
gg2 <- ggplot2::ggplot(data = dplyr::filter(df_co2_l, Pais %in% top_bottom),
ggplot2::aes(Ano, CO2_MT, group = Pais, color = Pais)) +
ggplot2::geom_line() +
ggplot2::geom_point(size = 2) +
ggplot2::labs(color = "Bottom five") +
ggplot2::theme_minimal()
gg1/gg2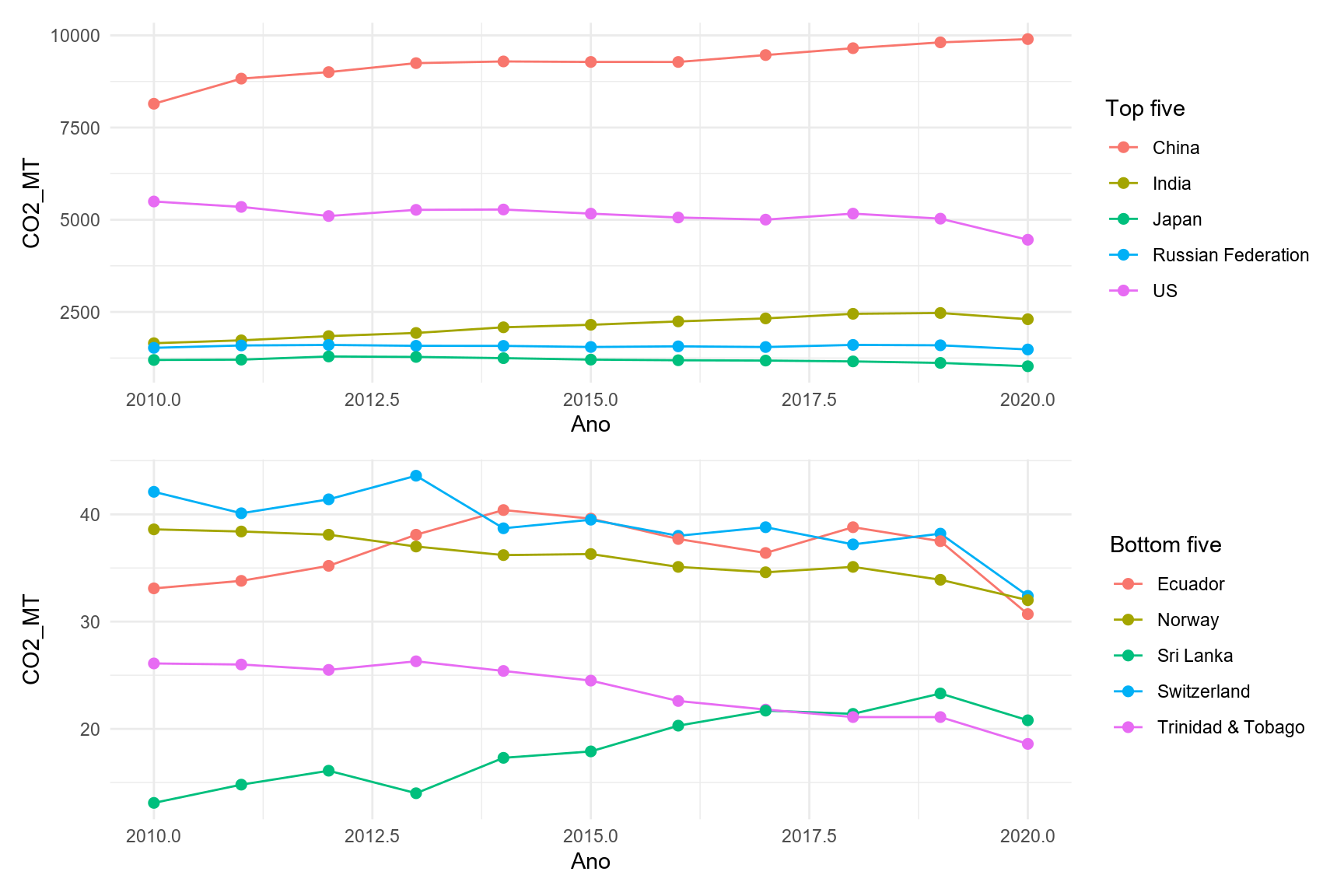
Parece que agora ficou um pouco melhor. Contudo, a ideia era falar sobre o uso do pacote que extrai a tabela do PDF. Ele ainda tem várias funcionalidades bacanerrímas. Precisa explorá-lo.
Bom trabalho!