
Importar tabela de PDF no R - Parte 2
Na primeira parte do post que eu utilizei o Tabulizer, lá no começo do ano, mostrei a função extract_tables, a qual repito aqui. Um plus em referência à primeira postagem é que aqui veremos o gráfico chamado aluvial.
Como exemplo, vou utilizar o restado do processo seletivo da Escola Nacional de Saúde Pública (ENSP) para o programa de Saúde Pública, turma 2022. Neste processo, os candidatos realizaram duas provas e utilizaremos as notas em cada prova para nosso gráfico.
Primeiro, vamos olhar a formatação da tabela do pdf :
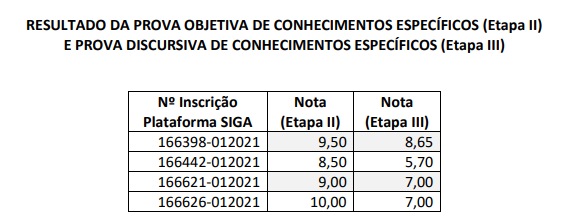
Este processo seletivo, como todo ato de ofício público, está publicizado no site da ENSP. Os nomes dos candidatos estão “protegidos” pelo código de inscrição, embora não seja ilegal a publicização dos nomes.
Percebemos que nossa tabela tem três colunas, sendo a primeira referente a indexação do candidato, a segunda a nota na etapa, na qual o processo denomina etapa II, e a terceira coluna seria a nota na etapa III.
Vamos extrair esta tabela diretamente do arquivo:
url <- 'http://ensino.ensp.fiocruz.br/documentos_upload/Resultado_das_ETAPAS_II_e_III_Prova_Espec%C3%ADfica_Doutorado_SP.pdf'
tab <- tabulizer::extract_tables(url)Vamos avaliar o que conseguimos de retorno:
dplyr::glimpse(tab)## List of 2
## $ : chr [1:34, 1:3] "No Inscrição" "Plataforma SIGA" "166398-012021" "166442-012021" ...
## $ : chr [1:23, 1:3] "No Inscrição" "Plataforma SIGA" "167200-012021" "167206-012021" ...A função extrac_tables possui um parâmetro chamado output que tenta converter o resultado retornado em data.frame (entre outros formatos). Maaas, vamos dar uma volta para resolver. Será mais sadio. Precebemos que retornou uma lista com dois elementos. Estes elementos são vetores do tipo character que corresponde às tabelas da primeira e segunda página do arquivo.
Vamos fazer um truque para montar nosso data.frame, anexando o primeiro e segundo elemento e já transformando em uma tibble e, além disso, já formatando o título, usando a função clean_names do pacote janitor (muuito útil). Usamos o parâmetro .name_repair para que as colunas fiquem como estão, por enquanto:
tab_f <- rbind(janitor::clean_names(tibble::as_tibble(tab[[1]], .name_repair = "minimal")),
janitor::clean_names(tibble::as_tibble(tab[[2]], .name_repair = "minimal")))Agora, vamos consertar os errinhos na mão mesmo:
tab_f <- tab_f[-c(1,2,35,36),]E agora, vamos corrigir formato, tirar a vírgula, converter para número e arrendondar para facilitar nosso entendimento, além de transformar as colunas em factor. Também vamos criar uma nova coluna chamada nota, que será útil para nosso gráfico. Percebam que é uma arrumação boa na tabela.
tab_f <- dplyr::mutate(tab_f,
v2 = as.numeric(gsub(',', '.', x_2)),
v3 = as.numeric(gsub(',', '.', x_3)),
v4 = factor(trunc(v2), levels = 1:10),
v5 = factor(trunc(v3), levels = 1:10),
nota = ifelse(v3 >= 7, "7-10", "1-6"))Agora, para nosso gráfico aluvial, precisamos ter um consolidado de candidatos por nota:
tab_c <- dplyr::count(tab_f, v4,v5, nota)E vamos para nosso gráfico. Notem que, primeiro, temos fazer um truque para que meu site interprete bem o pacote ggalluvial . Mas vocês podem evitar isso apenas chamando o pacote via library.
StatStratum <- ggalluvial::StatStratumggplot2::ggplot(data = tab_c,
ggplot2::aes(axis1 = v4, axis2 = v5, y = n)) +
ggplot2::scale_x_discrete(limits =
c("Nota na \nProva Objetiva",
"Nota na \nProva Discursiva"),
expand = c(.2, .05)) +
ggplot2::scale_y_continuous(breaks = seq(0,sum(tab_c$n),10)) +
ggplot2::ylab("Nùmero de alunos") +
ggalluvial::geom_alluvium(ggplot2::aes(fill = nota), show.legend = F) +
ggalluvial::geom_stratum(size = 0.1) +
ggplot2::scale_fill_brewer(type = "qual", palette = "Set1") +
ggplot2::geom_text(stat = "stratum", ggplot2::aes(label = ggplot2::after_stat(stratum))) +
ggplot2::theme_minimal()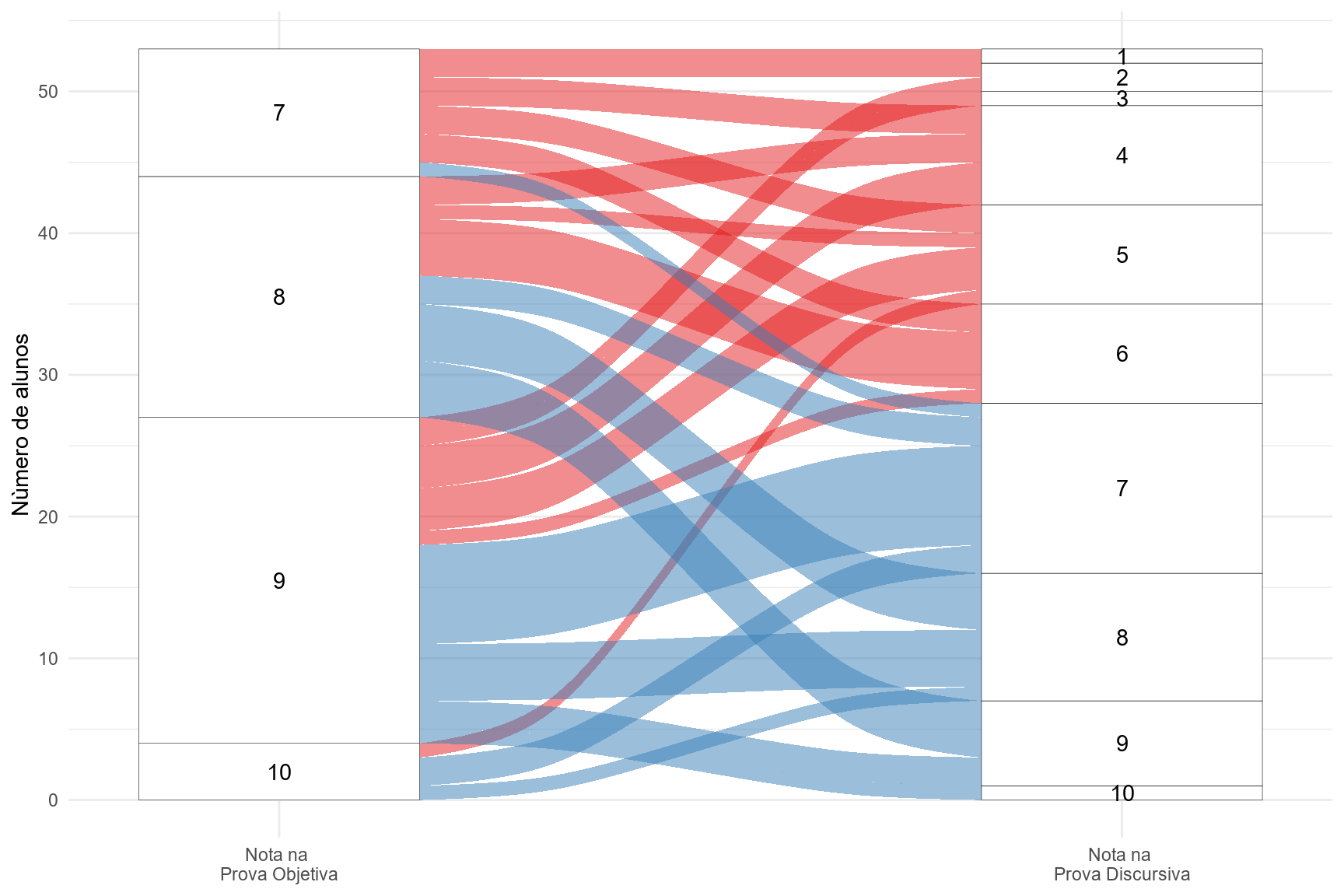
E temos nosso gráfico. Podemos perceber que alguns candidatos que conseguiram passar na prova objetiva (ou segunda etapa), iveram notas bem inferiores a sete na prova discursiva. Inclusive, chama a atenção alguns que obtiveram nota maior que 9 na prova 1 e não conseguiram aprovação na prova 2.
Enfim, temos mais um exemplo de uso da função e mais um exemplo de visualização de dados.
Sugiro que, caso tenham dúvidas, tentem revisar o help das funções e pacotes. Nada apresentado aqui é muito cabuloso ou misterioso.
Bom trabalho!!